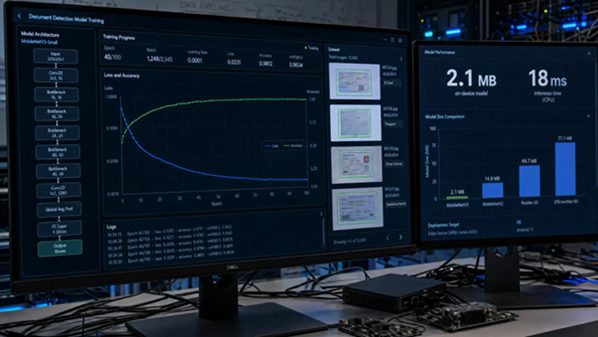
Deploying AI-powered document detection on mobile devices presents a fundamental engineering constraint: the models that deliver the highest accuracy on server hardware are typically far too large and too computationally demanding to run efficiently on a smartphone.
A full-scale document detection model that performs well on a cloud GPU may require hundreds of megabytes of storage and consume enough processing power to drain a mobile battery within minutes. Neither outcome is acceptable for a production application that users interact with in real time.
Organizations that have developed this capability, with OCR Studio serving as a representative example of platforms deploying document processing SDKs for mobile and edge environments, have demonstrated that well-designed compact models can achieve accuracy within a few percentage points of their full-scale counterparts while running at practical speeds on mid-range consumer hardware.
What Is a Lightweight Neural Network for Document Detection?
A lightweight neural network for document detection is a machine learning model designed to locate and classify identity documents within a camera frame, optimized for execution on devices with constrained computational resources such as mobile phones, tablets, and embedded systems. In other words, it performs the same detection task as a full-scale model but within tight bounds on model size, memory usage, and inference latency.
The detection task itself involves two subtasks that the model must handle jointly.
- Localization: identifying the bounding box or corner points of the document within the image frame, regardless of its position, orientation, or distance from the camera.
- Classification: determining the document type, such as passport, national ID card, or driver’s license, and in some implementations the issuing country, based on visual features of the detected document.
What is also important here is that on-device detection is typically the first stage in a longer pipeline. Once the document is localized and classified, subsequent stages handle OCR, field extraction, and authenticity checks. The lightweight detection model’s role is to produce a reliable, well-framed document region for the next stage, not to perform the entire verification task itself. Its performance requirements are therefore defined by both its own accuracy and its contribution to the overall pipeline quality.
Architectural Approaches for Lightweight Document Detection
Several model architectures have proven effective for on-device object detection tasks and can be adapted for document detection specifically. Understanding the trade-offs between them helps teams select the right starting point for their training effort.
MobileNet-Based Architectures
MobileNet and its successors, MobileNetV2 and MobileNetV3, were designed from the ground up for mobile inference efficiency. They use depthwise separable convolutions, a technique that factorizes standard convolution operations into two smaller operations, reducing the computational cost by roughly an order of magnitude relative to standard convolutions while preserving most of the feature extraction capability. These architectures are well suited as backbone networks for document detection models and are supported natively by TensorFlow Lite and Core ML, the two dominant on-device inference frameworks.
EfficientDet-Lite
EfficientDet-Lite is a family of detection models derived from the EfficientDet architecture, specifically adapted for mobile and edge deployment. It uses compound scaling to balance network depth, width, and input resolution, producing models across a range of size-accuracy trade-offs. EfficientDet-Lite0 and Lite1 are particularly relevant for document detection on mid-range devices, offering strong detection quality at model sizes well below 10 megabytes.
YOLO Variants for Edge Deployment
YOLOv5n and YOLOv8n, the nano variants of the YOLO family, are among the smallest real-time detection architectures available and can be converted to TensorFlow Lite or ONNX format for on-device deployment. These models sacrifice some accuracy relative to larger YOLO variants but offer inference speeds that make real-time document frame detection feasible on a wide range of mobile hardware. Given this speed advantage, they are particularly well suited to the document capture guidance use case, where the model must run continuously as the user aligns the document in the camera frame.
Training Data Requirements and Augmentation Strategies
Model accuracy on real-world document detection tasks depends heavily on the quality and diversity of the training dataset. A lightweight model trained on a narrow dataset will generalize poorly to conditions that differ from its training distribution, which in a production document capture application means failing on a significant share of real user sessions.
Dataset Composition
A training dataset for document detection should include, but not be limited to: documents from all target country and document type combinations, captured across a range of lighting conditions including harsh directional light and low ambient light, at multiple distances and angles, against both plain and textured backgrounds, with a proportion of partially occluded or angled documents that represent edge cases in real usage. The majority of training failures in production can be traced to insufficient coverage of one or more of these variation dimensions.
Data Augmentation Techniques
Because collecting annotated training images at sufficient scale is expensive, augmentation is essential for expanding effective dataset size and improving generalization. The most widely used options for document detection include random rotation and perspective transforms to simulate varied document angles, color jitter and brightness variation to simulate different lighting environments, motion blur to simulate handheld camera movement, and random cropping with partial occlusion to train robustness to partially visible documents.
What is also important here is that augmentation should be applied consistently during training but not during evaluation. Evaluating on augmented data will produce inflated accuracy metrics that do not reflect real-world performance. A separate held-out test set of unaugmented real captures is the only reliable performance measure.

Model Compression and Optimization for On-Device Inference
Even after selecting a lightweight architecture and training it on a diverse dataset, additional optimization steps are typically required to achieve the inference latency and model size targets needed for a production mobile application. The following techniques are the most widely applied.
Quantization
Post-training quantization converts the model’s floating-point weights to lower-precision integer representations, typically 8-bit integers, reducing model size by approximately 75 percent and significantly improving inference speed on hardware with integer arithmetic acceleration. TensorFlow Lite and Core ML both support 8-bit quantization natively. Quantization-aware training extends this by simulating quantization effects during the training process itself, typically recovering accuracy that is lost with post-training quantization alone.
Pruning
Structured pruning removes entire filters or channels from the network that contribute least to the model’s output, producing a smaller model that can be retrained to recover accuracy. This approach is effective when combined with knowledge distillation, described below, and can reduce model size by 30 to 50 percent with minimal accuracy loss when applied carefully. We recommend iterative pruning cycles rather than one-shot pruning, as gradual weight removal allows the remaining network to adapt more effectively.
Knowledge Distillation
Knowledge distillation trains the lightweight model, referred to as the student, to reproduce the output distributions of a larger, more accurate model, referred to as the teacher. Thanks to this technique, the student model learns from the teacher’s soft probability outputs rather than only from the hard labels in the training data, which conveys more information per training sample and typically produces a more accurate lightweight model than training on labels alone.
What a Reliable On-Device Document Detection Model Should Have
Teams building or evaluating lightweight document detection models for production use should look for the following characteristics before deployment.
- Inference latency under 100ms on mid-range hardware. Real-time document frame guidance requires the model to process each camera frame fast enough to provide feedback without perceptible delay. You should attentively analyze latency on the lowest-specification device the application will support, not only on high-end test devices.
- Model size under 10MB after quantization. App store size limits and user download tolerance impose practical constraints on model size. Pay attention to whether the size target is met after quantization and without compression artifacts that degrade accuracy.
- Robust performance across lighting and angle variations. Accuracy should remain high across the full range of conditions a real user might encounter. It will be helpful to evaluate the model specifically on low-light captures and extreme perspective angles, as these are the conditions where lightweight models most commonly fail.
- TensorFlow Lite or Core ML compatibility. The model should be exportable to the on-device inference format used by the target platform without requiring custom operators that are not supported natively. Custom operator dependencies create maintenance overhead and may fail across framework versions.
- Integration with a broader document processing pipeline. Typical integrations include a document quality assessment layer, an OCR engine, and a field extraction module. The detection model’s output format should be compatible with the inputs expected by these downstream components.
How to Approach Training a Lightweight Document Detection Model
The following steps outline a practical training process for teams developing on-device document detection capabilities.
- Start with a pretrained backbone, not random initialization. Using a MobileNet or EfficientDet-Lite backbone pretrained on ImageNet drastically reduces training time and data requirements compared to training from scratch. Transfer learning allows the model to start with general visual feature representations and fine-tune them for the document detection task.
- Curate a diverse annotation dataset before training. We recommend annotating at least several thousand images per document type, covering the full range of variation dimensions described earlier. Annotation quality matters as much as annotation quantity. Consistent bounding box labeling conventions and regular quality checks during annotation will reduce the noise in the training signal.
- Apply quantization-aware training from the start rather than as a post-processing step. Quantization-aware training produces models that are more robust to the accuracy loss associated with weight quantization. Building it into the training loop from the beginning avoids the need for separate post-training recovery fine-tuning cycles.
- Evaluate on a held-out real-capture test set at every checkpoint. Augmentation-based validation scores are not a reliable indicator of real-world performance. Deploy a fixed test set of unaugmented real document captures and track performance on this set throughout training to detect overfitting early.
- Profile inference latency on target hardware before finalizing the model. Theoretical FLOP counts and parameter counts are poor predictors of actual inference latency on specific mobile hardware. Always profile the exported TFLite or Core ML model on the actual target device before declaring the model production-ready.
Training a lightweight neural network for on-device ID document detection is an engineering discipline that requires careful choices at every stage, from architecture selection and dataset curation through training technique and deployment optimization. The goal is a model that is small enough to deploy on a mobile device, fast enough to run in real time within a document capture flow, and accurate enough to serve as a reliable first stage in a production verification pipeline.
Teams who invest in quantization-aware training, knowledge distillation, and diverse training data create models that perform consistently in real-world conditions rather than only on clean benchmark datasets. The combination of these techniques, applied systematically, makes it possible to achieve on-device document detection accuracy that was previously available only in cloud-based processing pipelines, enabling the privacy-preserving, low-latency verification applications that users and regulators increasingly require.